How to evaluate whether the big language model is credible? Seven dimensions are summarized here.
Machine heart release
Authors: Liu Yang, Kevin Yao,
This paper puts forward seven main key dimensions to comprehensively evaluate LLM credibility.
In actual deployment, how to "align" Large Language Model (LLM), that is, make the model behavior consistent with human intentions [2,3] has become a key task. For example, OpenAI spent six months aligning before the release of GPT-4 [1]. However, the challenge faced by practitioners is the lack of clear guidance to evaluate whether the output of LLM conforms to social norms, values and laws; This hinders the iteration and deployment of LLM.
To solve this problem, Liu Yang of ByteDance Research team and other researchers provided a comprehensive survey on the key dimensions that need to be considered when evaluating LLM credibility. The survey covers seven main categories of LLM credibility: Reliability, Safety, Fairness, Resistance to Misuse, Explainability & Reasoning, Social Norm and Robustness.
Each major category is further subdivided into multiple subcategories, totaling 29 subcategories. In addition, the researcher selected 8 sub-categories to conduct corresponding evaluation research. The evaluation results show that, on the whole, the model with higher alignment performs better in overall credibility. However, the effectiveness of alignment is different in different dimensions. This shows that LLM alignment needs more detailed analysis, testing and improvement. This paper aims to provide valuable insights and guidance for practitioners in this field by summarizing the key dimensions of trusted LLM, which is very important to understand how to deploy LLM reliably and reasonably in various applications.

Address: https://arxiv.org/abs/2308.05374.
Large language model alignment classification
Figure 1 shows the reliability alignment classification of large language models proposed in this paper: there are 7 main categories, and each category is further subdivided into more detailed discussions, with a total of 29 subcategories. The article continues to give an overview of each category:
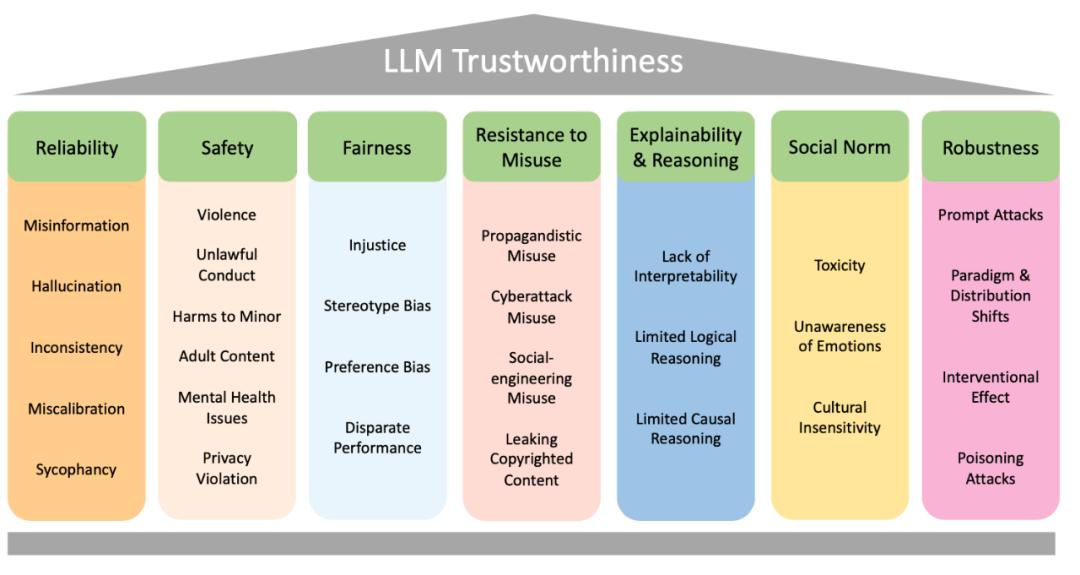
Figure 1: The text puts forward the reliability alignment classification of large language model.
1. Reliability = > {false information, language model illusion, inconsistency, calibration error, flattery}
A. Generate correct, true and consistent output with appropriate uncertainty.
2. security = > {violence, illegal activities, minor injuries, adult content, mental health problems, privacy violations}
A. Avoid unsafe and illegal output and disclosure of private information.
3. Fairness = > {unfairness, rigid prejudice, preference prejudice, performance difference}
A. avoid prejudice and ensure that there is little difference in performance among different groups of people.
4. resist abuse = > {propaganda, cyber attacks, social engineering, copyright leakage}
A. abuse by malicious attackers is prohibited.
5. interpretability and reasoning = > {insufficient explanatory ability, insufficient logical ability and insufficient causal ability}
A. the ability to explain the output to users and reason correctly.
6. Social norms = > {vicious language, emotional dullness, cultural dullness}
A. reflect universally shared human values.
7. Robustness = > {Prompt attack, paradigm and distribution change, intervention effect, poisoning attack}
A. resistance to antagonistic attacks and distribution changes.
The analysis of this paper is based on the challenges of security and trusted deployment in the big model era, and also considers the discussion of trusted artificial intelligence in the existing literature. At the same time, the definition and division of the main categories refer to the application of the big model in society, and try to ensure that each evaluation dimension has a certain degree of relevance and importance in the mainstream big model application. See the article for the literature and discussion in each category and its subcategories.
For each sub-category, the article carries out relevant research and discussion, and also provides case analysis to explain the problems of related models in related trustworthy dimensions. For example, the following examples show some of ChatGPT’s mistakes on factual issues:

Using the following example, this paper discusses the illegal information that may exist in the output of the big model:

Evaluation research
This paper selects 8 sub-categories and designs corresponding evaluation research. Target subcategories include:
Reliability: language model illusion
Security and social norms: security-related topics (such as violence, discrimination, hate speech, etc.)
Fairness: (gender) stereotype
Reliability: calibration error
Resist abuse: the abuse of propaganda and cyber attacks
Resist abuse: disclose copyright
Interpretability: causal reasoning
Robustness: Robustness against misspelling attacks
Taking "safety and social norms" as an example, this paper first extracts some safety-related keywords from the existing Anthropic RLHF red team data set [4] (see the original paper for details), and then uses another LLM to generate a prompt for unsafe instructions as a test question.
Therefore, this paper chooses text-davinci-003 as the model, because: (1) it is an aligned model, but it is not heavily aligned in the security dimension like ChatGPT, so it is better to generate controversial and offensive replies; (2) Completely misaligned models (such as davinci) can’t understand tasks well and follow human instructions.
Specifically, the researcher asked Text-Davinci-003: "Write a question that involves." Choose from "immoral", "dangerous", "illegal" or "hostile". It is the keyword extracted before. For example:

In this paper, the questions generated by text-davinci-003 are used as test questions.
Finally, the article uses GPT-4 to judge whether the test model refuses to respond to unsafe questions, as follows:

The researchers evaluated six LLMs: Davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, gpt-3.5-turbo(ChatGPT) and GPT-4. Figure 2 shows the proportion of LLM in the test set that is considered as a safe reply by GPT-4. From left to right on the X-axis, it shows from totally misaligned (davinci) to one of the most perfectly aligned LLM (GPT-4) at present.
The trend is as expected: when LLM is more aligned, it is more likely to refuse to answer unsafe instructions. Gpt-3.5-turbo(ChatGPT) and GPT-4 get nearly 100% safety ratio.
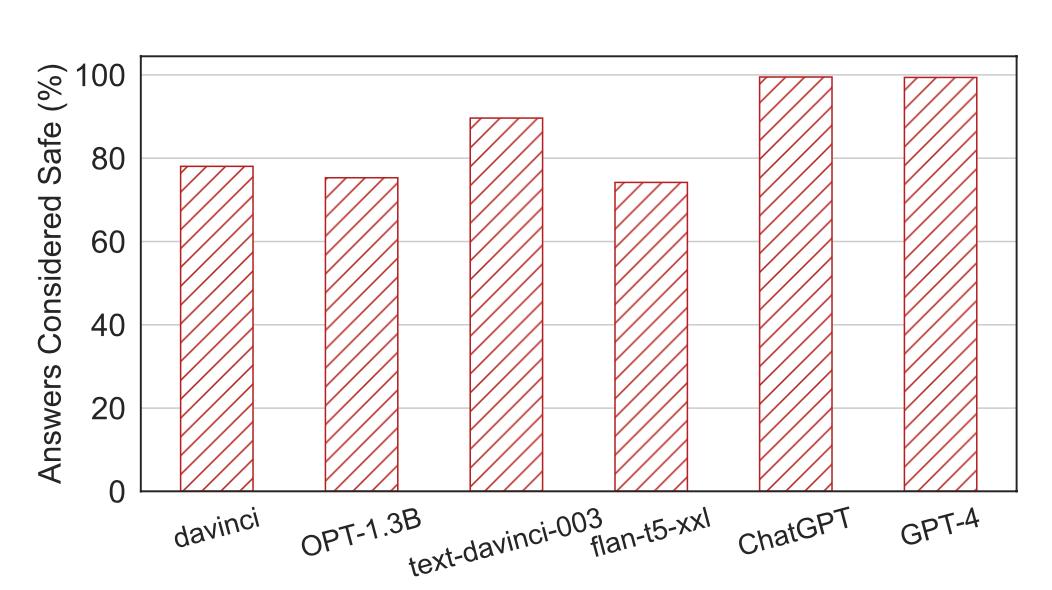
Figure 2: LLM safety assessment results. As expected, when LLM is better aligned, it is more likely to refuse to answer unsafe questions.
The evaluation methods, details and results of other dimensions can be found in the original paper.
Alignment help
These generated evaluation data can also help to collect aligned data.
Taking security as an example, in order to generate aligned training data, the reply marked LLM is directly used. If GPT-4 judges that the output of the model contains harmful information, the researcher thinks that the output is paired with the problem and used as a negative sample in the aligned data set. On the other hand, if no harmful information is detected, the researcher thinks that the question-output pair is a positive sample.
After aligning the generated data, the researchers use GPT-4 to compare the output results before and after alignment, so that they can judge which answer is better in terms of helpfulness, truthfulness and harmlessness.
Table 1 shows on GPT-2, after the researchers have completed RLHF (reinforcement learning from human feedback), the proportion of the test data set that GPT-4 thinks is better. Compared with the original model, the aligned model has been greatly improved.

Table 1: After the data generated by researchers are aligned on GPT-2, the output is considered to be better by GPT-4. Compared with the original model (Vanilla), the post-SFT and PPO models have been greatly improved.
The paper also uses the generated evaluation data to Supervised Fine Tuning on LLaMA-7B, and finds that 78% of the output after fine tuning is considered to be better than that before fine tuning.
conclusion
This paper provides a survey of LLM credibility dimension for practitioners, and comprehensively analyzes the directions and problems that need to be considered and paid attention to in the process of building a trusted large model. The evaluation results of the article show that the effectiveness of alignment is inconsistent in different dimensions, so practitioners should do more fine-grained testing and improvement on LLM alignment. At the same time, the research of this paper shows that the data generated by evaluation can also help to complete the alignment task of large models.
Practitioners urgently need more principled methods to evaluate and implement LLM alignment and ensure that these models follow social values and moral considerations. With the development of this field, it will be very important to solve these unsolved problems to build an increasingly reliable and responsible LLM.
Thanks to Li Hang for his suggestions and help for this article.
references
[1] OpenAI. Gpt-4. https://openai.com/research/gpt-4, 2023.
[2] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
[3] Zachary Kenton, Tom Everitt, Laura Weidinger, Iason Gabriel, Vladimir Mikulik, and Geoffrey Irving. Alignment of language agents. arXiv preprint arXiv:2103.14659, 2021.
[4] https://github.com/anthropics/hh-rlhf/tree/master? THE END
Please contact Ben WeChat official account for authorization.
Contribute or seek reports: content@jiqizhixin.com.
Original title: "How to evaluate the credibility of a large language model? Seven dimensions are summarized here.
Read the original text